
3
Section
Retrieval-Augmented Generation (RAG)
What is RAG?
What is RAG?
RAG (Retrieval-Augmented Generation) is an AI technique that combines a retriever with a generator to allow language models to answer questions based on external, up-to-date, or private knowledge that isn't part of their original training data.
What does this really mean though?

RAG Use Case Example
Company policy chatbot
you want to build a

Company policy chatbot
you want to build a
but no LLMs were trained on your company policy docs, so you...
Augment the LLMs training by passing your own data to the prompt context
but you can't just dump in all your docs...
but you can't just dump in all your docs
That would:
1. cost too much
2. be slow
3. and be more likely to produce hallucinations

You retrieve the docs most relevant to the user request
so before you pass in your policy docs data...

but how do you know what's most relevant?
You could do traditional keyword searching
that's been around forever...
SELECT * FROM docs WHERE content
LIKE '%[user request]%'
What tools are available for this?
Vector embeddings!
What are vector embeddings?
So instead you want to do a fuzzier, more semantic meaning kind of search
but this is likely to miss a lot of relevant docs.

What are vector embeddings?
Numerical representations of text designed so that similar meanings are close together in vector space, even if the exact words are different.
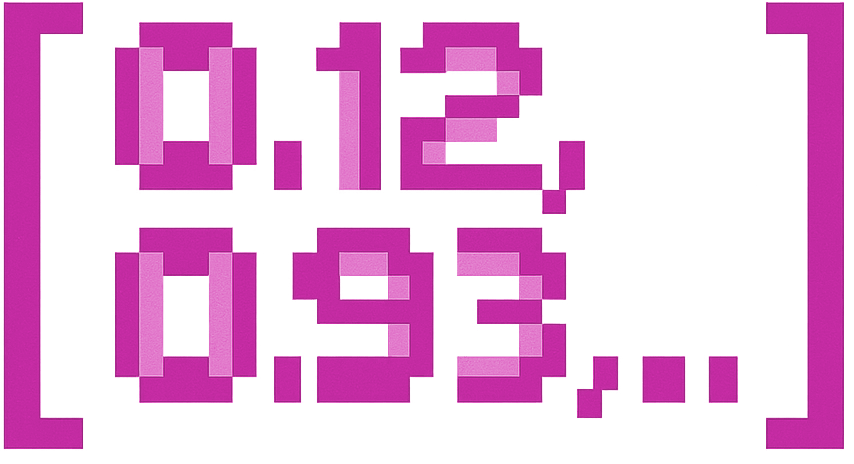
Some random string of text
===
For example...
- “Reset password” → [0.12, -0.93, 0.56, ...]
- “Forgot login credentials” → a vector very close to the one above
or...
- “Apple” → [0.12, -0.93, 0.56, ...]
- “Banana” → a vector pretty close to the one above
- "House" → a vector NOT close to either of these
there are many of them out there...
All major LLMs have them (OpenAI, etc) or you can use Ollama to use open source models
With AI of course... specifically an embeding model
How do you create these embeddings?





So you pick one, create vector embeddings for all your docs, and store them in your own vector databse


Vector

Vector
4. And finally return a grounded/informed response
Then at the time of an end user question...
2. query the vector DB embeddings within a certain distance of that query
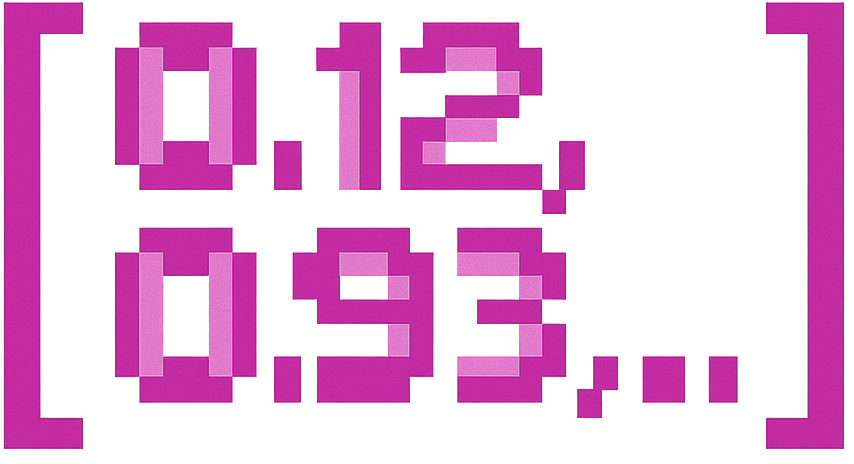
3. pass on the matched context to the Generative AI
1. make an embedding of the user question
(important you use the same embedding model!)

Summary of RAG Process
- Generate embeddings of your data
- Store the embeddings in a vector database
- (R)etrieve the data most relevant to their request.
- (A)ugment the user's prompt by adding the query results
- (G)enerative AI (the LLM) can now generate a relevant response
- And return it to the user
A process totally separate from and before the users' request
At request time (ie the moment the user prompts the chatbot)
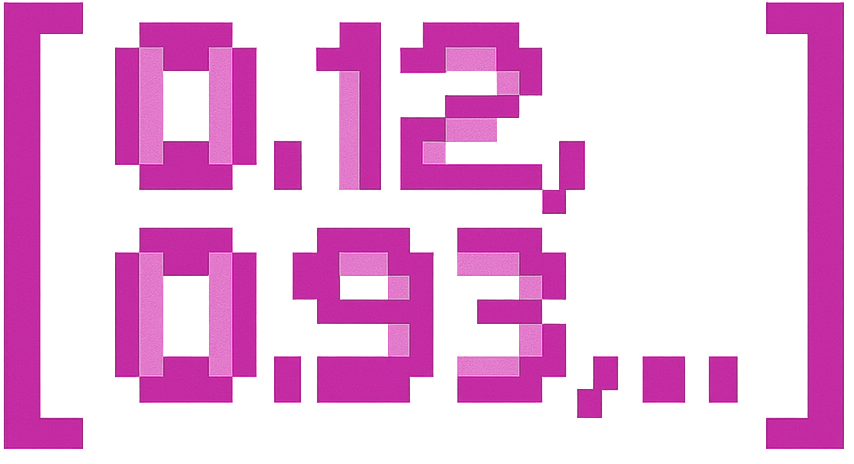
Vector
Vector
Vector

What vector database solutions exist?
What vector database solutions exist?
Specialized RAG SAAS
offer vector db hosting plus more


Vector DB Solutions
What vector database solutions exist?



(ie. sqlite flavor created by
what we're using in the exercise project)

via pgvector extension
Yes this means you can do RAG with

or postgres


Cloudflare Vectorize DB


+ more!
RAG Code Example
// Generate Embeddings
import fs from "fs/promises";
import path from "path";
import dotenv from "dotenv";
import OpenAI from "openai";
import { useDb, schema } from "../server/utils/db";
import { sql } from "drizzle-orm";
dotenv.config();
const folder = "company_policies";
const openai = new OpenAI({
apiKey: process.env.NUXT_OPENAI_API_KEY!,
});
const db = useDb();
await db.run(sql`
CREATE INDEX IF NOT EXISTS company_policies_vector_idx
ON company_policies(libsql_vector_idx(embedding));
`);
const directory = path.join(process.cwd(), folder);
async function getMarkdownFiles(dir: string): Promise<string[]> {
const files = await fs.readdir(dir);
return files.filter((f) => f.endsWith(".md")).map((f) => path.join(dir, f));
}
// Chunking splits large files into smaller parts to fit token limits and improve semantic search.
async function chunkText(text: string, maxTokens = 50): Promise<string[]> {
// Split by paragraphs (empty lines)
const paragraphs = text.split(/\n\s*\n/);
const chunks: string[] = [];
let current = "";
for (const para of paragraphs) {
if ((current + para).length > maxTokens * 4) {
if (current.trim()) chunks.push(current.trim());
current = "";
}
current += para + "\n\n";
}
if (current.trim()) {
chunks.push(current.trim());
}
return chunks;
}
async function embedAndStore() {
const files = await getMarkdownFiles(directory);
for (const file of files) {
const content = await fs.readFile(file, "utf-8");
const chunks = await chunkText(content);
console.log(file, chunks.length);
for (const [i, chunk] of chunks.entries()) {
const res = await openai.embeddings.create({
model: "text-embedding-ada-002",
input: chunk,
});
if (!res.data[0]) throw new Error("Failed to generate embedding");
const embedding = res.data[0].embedding;
await db.insert(schema.companyPolicies).values([
{
filepath: file,
content: chunk,
chunkNumber: i,
embedding: sql`vector32(${JSON.stringify(embedding)})`,
},
]);
}
console.log(`✅ Embedded ${file}`);
}
}
embedAndStore().catch(console.error);
Walk through together
RAG Code Example
// Retreive results similar to query
import dotenv from "dotenv";
import OpenAI from "openai";
import readline from "readline";
import { useDb, schema } from "../server/utils/db";
import { sql } from "drizzle-orm";
dotenv.config();
const openai = new OpenAI({
apiKey: process.env.NUXT_OPENAI_API_KEY!,
});
const db = useDb();
async function getQueryEmbedding(query: string): Promise<number[]> {
const res = await openai.embeddings.create({
model: "text-embedding-ada-002",
input: query,
});
if (!res.data[0]) throw new Error("Failed to generate embedding");
return res.data[0].embedding;
}
// topK is the number of results to return
async function searchcompanyPolicies(query: string, topK = 5) {
const embedding = await getQueryEmbedding(query);
// Use vector_top_k to find the most similar vectors, then join with the actual table
// vector_top_k returns records with the primary key/rowid of matching rows
const matches = await db
.select({
id: sql`vt.id`,
content: schema.companyPolicies.content,
filepath: schema.companyPolicies.filepath,
chunkNumber: schema.companyPolicies.chunkNumber,
})
.from(
sql`vector_top_k('company_policies_vector_idx', vector32(${JSON.stringify(
embedding
)}), ${topK}) as vt`
)
.leftJoin(
schema.companyPolicies,
sql`${schema.companyPolicies.id} = vt.id`
);
console.log(`\n🔍 Top ${topK} results for: "${query}"\n`);
for (const [i, match] of matches.entries()) {
console.log(`--- Result ${i + 1} ---`);
console.log(`Source: ${match.filepath} (Chunk ${match.chunkNumber})`);
console.log(`Content: ${match.content?.substring(0, 200)}...`);
console.log("");
}
return matches;
}
function promptForQuery() {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
rl.question("🧠 Enter your question: ", async (query) => {
const answer = await answerQuery(query);
console.log(answer);
rl.close();
});
}
async function answerQuery(query: string) {
const matches = await searchcompanyPolicies(query);
const context = matches.map((match) => match.content).join("\n");
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: `You are a helpful assistant that answers questions about company policies.
You are given a context and a question. You should answer the question based on the context.
If you don't know the answer, say 'I don't know'.
<context>${context}</context>`,
},
{ role: "user", content: query },
],
});
if (!response.choices[0]) throw new Error("Failed to generate response");
const answer = response.choices[0].message.content;
return answer;
}
promptForQuery();
Walk through together
RAG:Other Considerations
There are plenty of ways you can fine-tune your RAG pipeline for your use case....
1. Number of Vectors to Retrieve (Top-K)
- Higher = more context, but increased latency and risk of irrelevant info.
- Lower = faster, but may miss important context.
- Typical values: 3–10 (can go higher for complex queries).
Why it matters: Determines how many documents (or chunks) are retrieved for the model to consider.
2. Vector Dimension Size
-
Higher dimensions = better accuracy, but larger DB size and slower queries.
-
Choose based on the model (e.g., OpenAI uses 1536, MiniLM is 384).
Why it matters: Higher dimensional vectors can encode more nuanced semantic meaning.
3. Chunk Size and Overlap
- Too large = sparse matches and harder for models to reason.
- Too small = context gets broken across chunks.
- Overlap helps maintain coherence between chunks.
Why it matters: Controls how the original documents are split.
Plus More
-
Document Metadata Filtering (adding more query parameters, for example)
- Embedding Model - price, speed, number of vector dimensions, etc
- Caching / Index Refresh Interval - too often is expensive, too rare creates stale results
- Retrieval Scoring Function - Different ways of measuring similarity (Cosine vs Euclidean vs Dot)
filter: { type: 'policy', language: 'en' }Don't be overwhelmed by the different options!